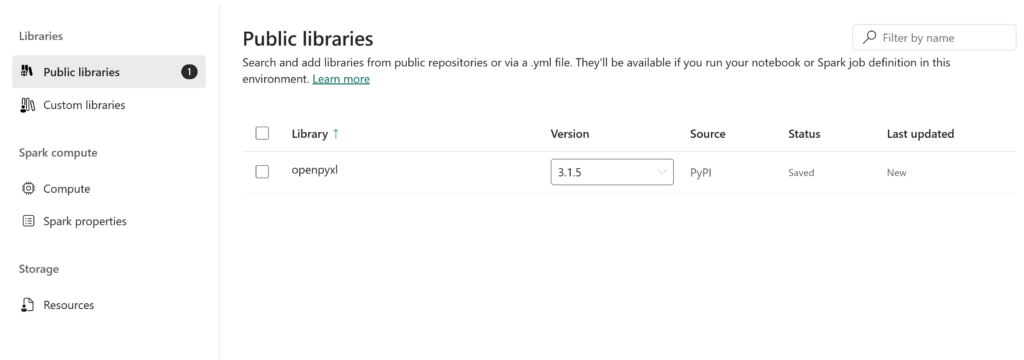
When writing Python code in notebooks there are a lots of packages that can be really useful to select and transform data like Pandas and PySpark. In this article you will learn how to get an overview of all the preinstalled packages and how to install new public packages from PyPi.
PyPi
PyPI, the Python Package Index (https://pypi.org), is a central repository for Python packages. It enables users to easily download and share Python software, fostering community-driven development. As the main hub for Python package management with tools like pip, PyPI is essential to the Python ecosystem.
Method 1: PIP Inline installation
PIP is the de facto package installer for Python, facilitating the installation and management of software packages from the Python Package Index (PyPI). It allows you to easily install, upgrade, and uninstall Python packages with simple command-line instructions.
For example to get an overview of the packages that are already installed inside your Fabric Environment you can use the following command:
# list packages
%pip list
Most popular Python packages are already installed in your Fabric Environment. To name a few: NumPy, Pandas, PySpark, Mathplotlib, Seaborn and Scikit-learn. To get information about a specific package:
# details package
%pip show openpyxl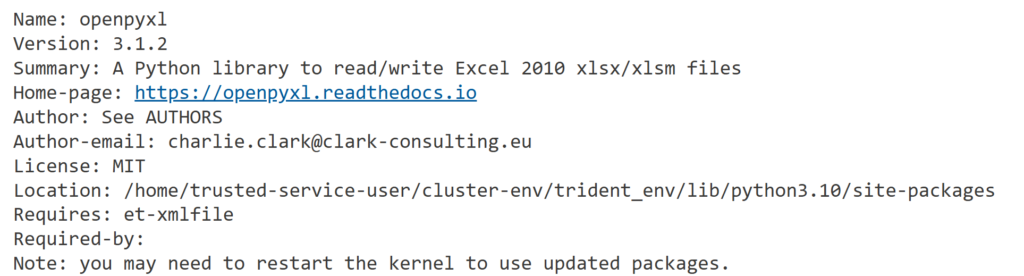
To install new packages inside your current notebook session you use the pip command install. This is very useful for onetime installations, the package will be gone when the Spark session ends.
# install package from PyPi
%pip install openpyxl
# install package with specific version
%pip install openpyxl==3.1.2Warning: !pip only installs a package on the driver node, not executor nodes ( Manage Apache Spark libraries – Microsoft Fabric | Microsoft Learn ).
Method 2: Workspace Installation
When manually installing with Pip the packages will only be installed in the Executor and Worker nodes ( Spark Introduction ) of the current Spark session used by the Notebook. This is not ideal for packages that you want to use in lots of notebooks, especially if they are interdependent. A better solution for this use case is to install the packages inside the environment that you are using. This can be either the default environment or the workspace or a custom one.
Step 1 Workspace Settings
Go to the Workspace Settings – Data Engineering/Science – Spark Settings – Environment. Here you can create a new Environment or select and existing one. Click on the link next to the name of the Environment to open up the settings screen:
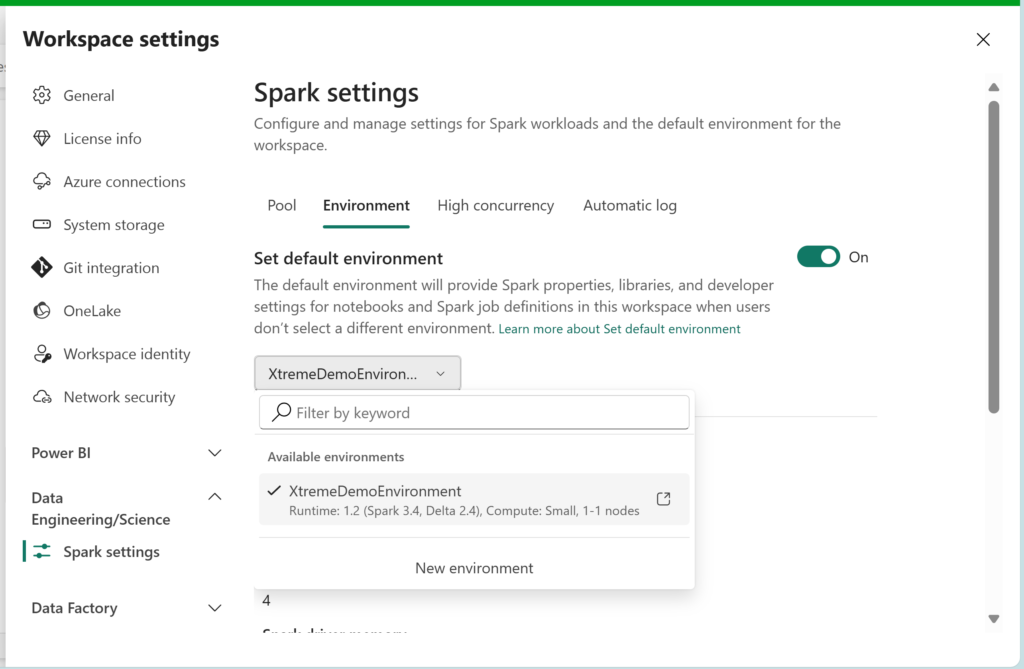
Step 2 Spark Environment Settings
In the Public Libaries section you can add a new package by clicking the “Add from PyPi” button:
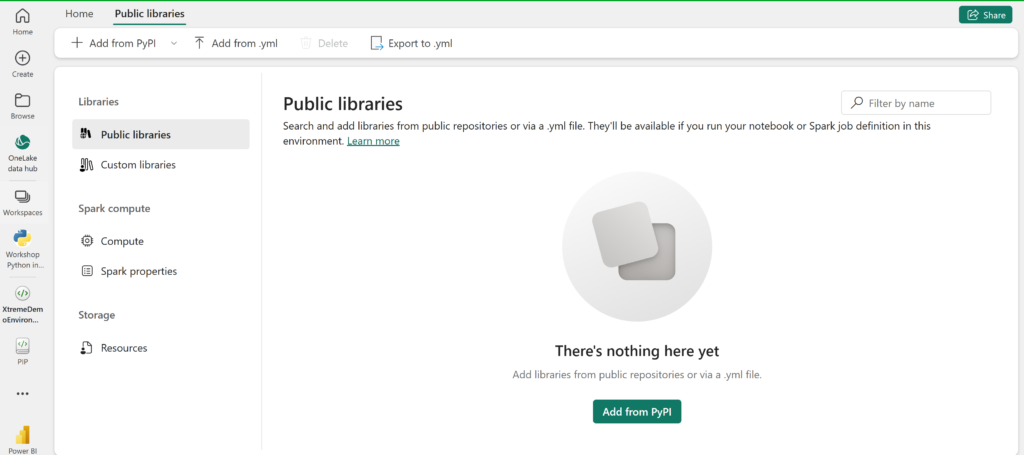
Type in the name of the PyPi package and click “Save”. After you “Publish” this new packages will be installed automatically in every Spark session in this Environment.